Conclusion
The random forest model I developed obviously has much room for improvement - it had low precision in predicting the streets that would be repaved in 2023 and, as a result, predicts few streets in 2024 will be repaved. This is likely due to a few reasons.
One could be that the variables I chose are not strong enough to predict paving needs. Information about, for example, the age of the utilities running underneath the street, may be stronger predictor whether the street would need repaving.
Another reason could be that the decision making process for street repaving is not very systematic or logical. I would expect that a street with more calls about potholes would be more likely to be repaved. I’d expect that a street where truck traffic is not allowed would be less likely to be repaved. The paving program provides little insight into the process behind choosing which roads to be repaved. The program provides a “Condition Index”, a score of the condition of the street, 0 being the lowest quality condition, 100 being the highest quality. A quick review of the streets being repaved in 2023 show that a majority have a condition index of 100.
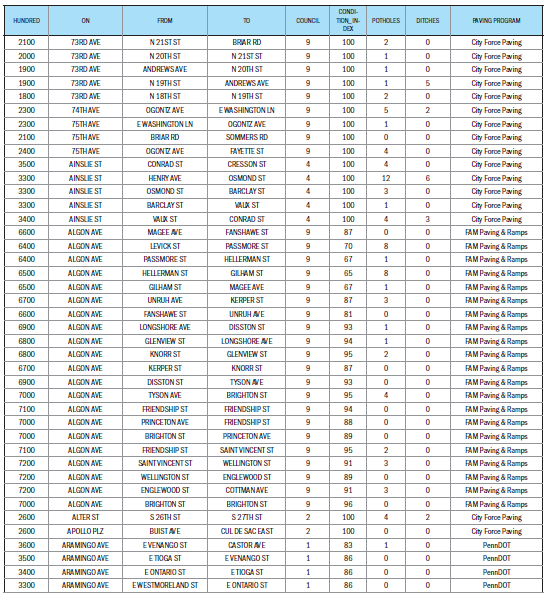
Why are these the streets being repaved? It seems like there are other priorities for repaving aside for the street condition, the safety of the street, and if the street was recently repaved.
Maybe it is just as my former Street Department coworkers said - somebody in their office, randomly picking streets. Even if there were more variables in the model, a strong model can’t be built if the decisions aren’t systematic.