C:\Users\epark\AppData\Local\Temp\ipykernel_21156\1834119373.py:11: FutureWarning: The default value of numeric_only in DataFrame.corr is deprecated. In a future version, it will default to False. Select only valid columns or specify the value of numeric_only to silence this warning.
sns.heatmap(street[cols].corr(), cmap='coolwarm', annot=True, vmin=-1, vmax=1);
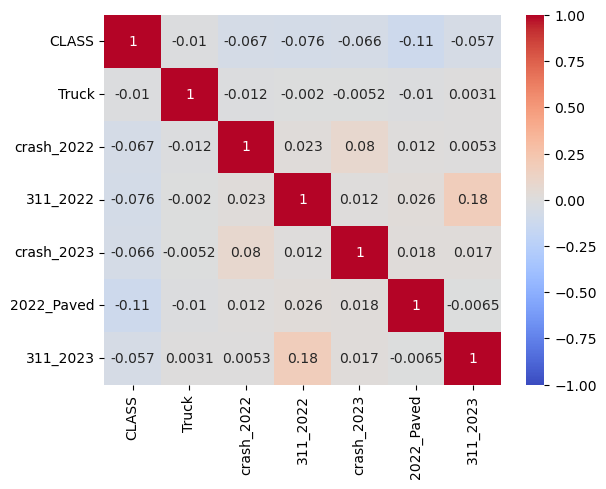
The correlation plot shows little correlation between any of the independent variables.
Now we can pull out the 2022 data to make our test and train set.
(1) Random Forest Model - A collection of decision trees, each trained on a random subset of the data. The final prediction is a majority vote of the individual tree predictions.
(2) XG Boost - A collection of decision trees, built sequentially, with each new tree correcting the errors of the previous ones.
(3) Logistic Regression Model - Uses the logistic function to transform a linear combination of input features into a probability score. The output is then thresholded to make binary (or multiclass) predictions.
(4) K-Nearest Neighbors - Classifies or predicts based on the majority class (for classification) in the feature space. The “nearest neighbors” are determined by a distance metric.
Preprocess Data
Code
numerical_features = ['crash_2022', '311_2022']categorical_features = ['CLASS', 'Truck', 'nearest_lts_score','2022_Paved']target_variable ='2023_Paved'# Creating feature and target dataframesX = street_2022_features[numerical_features + categorical_features]y = street_2022_features[target_variable]# Splitting the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# Creating a preprocessor for categorical featurestransformer = ColumnTransformer( transformers=[ ("num", StandardScaler(), numerical_features), ("cat", make_pipeline(SimpleImputer(strategy='constant', fill_value=0), # Fill missing values with 0 OneHotEncoder(handle_unknown="ignore")), # Apply OneHotEncoder categorical_features) ])
Random Forest Model
Code
# Make a random forest pipelinepipe = make_pipeline( transformer, RandomForestClassifier(n_estimators=20, random_state=42))# Fit on the training datapipe.fit(X_train, y_train);pipe.score(X_test, y_test)y_pred = pipe.predict(X_test)# Evaluate the modelaccuracy = accuracy_score(y_test, y_pred)print(f'Accuracy (Random Forest): {accuracy}')# Confusion Matrixprint('Confusion Matrix:')print(confusion_matrix(y_test, y_pred))# Classification Reportprint('Classification Report:')print(classification_report(y_test, y_pred))
That’s not a great model! The model is really good at predicting true negatives, but bad at predicting true positives - only 1% of true positives were predicted. The overall accuracy is high since most street segments are not being repaved. While it’s likely because the variables that are chosen aren’t great for the model, let’s try a few other models to see if anything can be improved.
XG Boost
Code
X_train_transformed = transformer.fit_transform(X_train)X_test_transformed = transformer.transform(X_test)# Create and train the XGBoost modelmodel = XGBClassifier()model.fit(X_train_transformed, y_train)# Make predictions and evaluate the modely_pred = model.predict(X_test_transformed)# Evaluate the modelaccuracy = accuracy_score(y_test, y_pred)print(f'Accuracy (XGBoost): {accuracy}')# Confusion Matrixprint('Confusion Matrix:')print(confusion_matrix(y_test, y_pred))# Classification Reportprint('Classification Report:')print(classification_report(y_test, y_pred))
The XG Boost model is worse than the random forest - 0% of true positives were predicted correctly.
Logistic Regression Model
Code
# Create a logistic regression model using make_pipeline with preprocessing stepslogistic_model = make_pipeline(transformer, LogisticRegression())# Train the modellogistic_model.fit(X_train, y_train)# Make predictions on the test sety_pred_logistic = logistic_model.predict(X_test)# Evaluate the modelaccuracy_logistic = accuracy_score(y_test, y_pred_logistic)print(f'Accuracy (Logistic Regression): {accuracy_logistic}')print('Confusion Matrix:')print(confusion_matrix(y_test, y_pred_logistic))print('Classification Report:')print(classification_report(y_test, y_pred_logistic))
C:\Users\epark\mambaforge\envs\musa-550-fall-2023\lib\site-packages\sklearn\linear_model\_logistic.py:460: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\epark\mambaforge\envs\musa-550-fall-2023\lib\site-packages\sklearn\metrics\_classification.py:1469: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
C:\Users\epark\mambaforge\envs\musa-550-fall-2023\lib\site-packages\sklearn\metrics\_classification.py:1469: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
C:\Users\epark\mambaforge\envs\musa-550-fall-2023\lib\site-packages\sklearn\metrics\_classification.py:1469: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
The logistic regression model is worse than the random forest - 0% of true positives were predicted correctly.
K-Nearest Neighbors
Code
# Transform the dataX_train_transformed = transformer.fit_transform(X_train)X_test_transformed = transformer.transform(X_test)# Create a KNN modelknn_model = KNeighborsClassifier()# Train the modelknn_model.fit(X_train_transformed, y_train)# Make predictions on the test sety_pred_knn = knn_model.predict(X_test_transformed)# Evaluate the modelaccuracy_knn = accuracy_score(y_test, y_pred_knn)print(f'Accuracy (KNN): {accuracy_knn}')print('Confusion Matrix:')print(confusion_matrix(y_test, y_pred_knn))print('Classification Report:')print(classification_report(y_test, y_pred_knn))